AEGIS-RAG

Reliable Retrieval-Augmented Generation for policy documents — with hybrid retrieval, cross-encoder reranking, and safe abstention when evidence is weak.
🚀 Try the live demo · 💻 View on GitHub
The Objective
AEGIS-RAG is a production-grade Retrieval-Augmented Generation system for reliable question answering over policy documents. It prioritizes retrieval quality, ranking precision, and safe abstention over flashy generation — designed for high-stakes domains where a confidently wrong answer is worse than no answer at all.
The Architecture & Methodology
The system follows a three-stage pipeline with strict separation of concerns:
- Hybrid Retrieval — Dense embeddings (E5-large-v2) + sparse BM25, fused via Reciprocal Rank Fusion with weighted contributions.
- Cross-Encoder Reranking —
ms-marco-MiniLM-L-6-v2reorders the top candidates by query-passage relevance. - Grounded Generation —
llama3.1:8bwith a strict system prompt that forces a canonical fallback string when the retrieved context doesn’t support an answer.
This separation enables independent optimization of each stage and makes failure modes traceable.
The Differentiator: Two-Layer Abstention
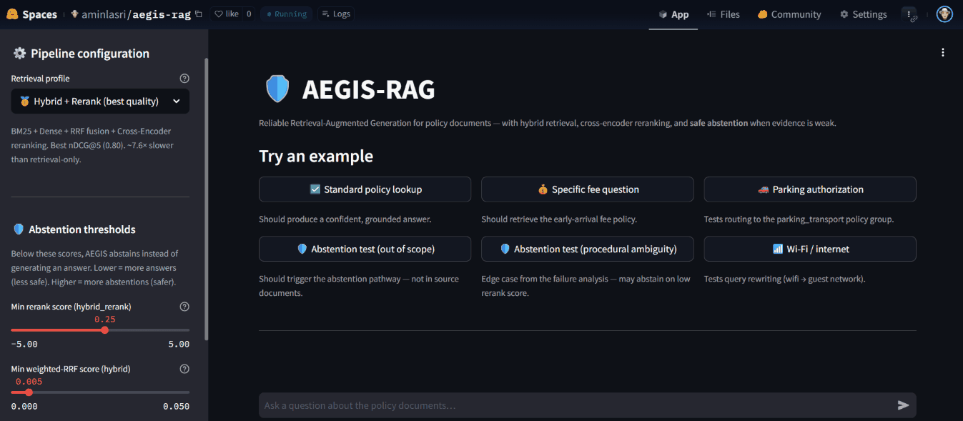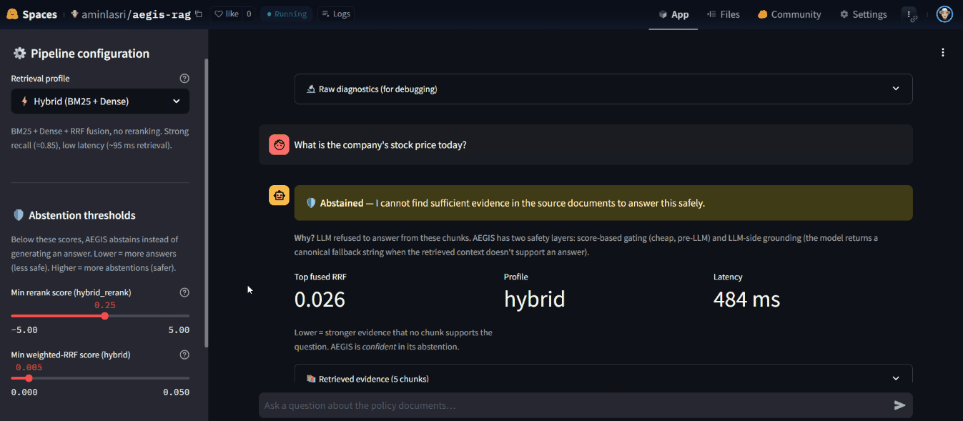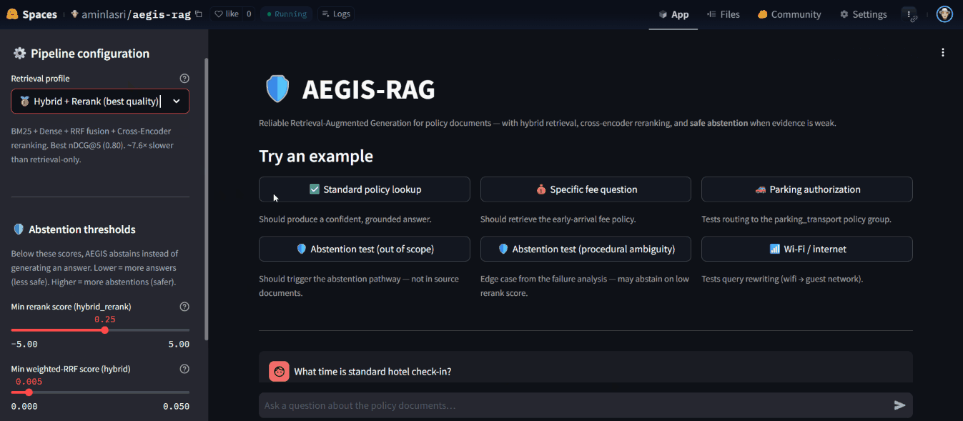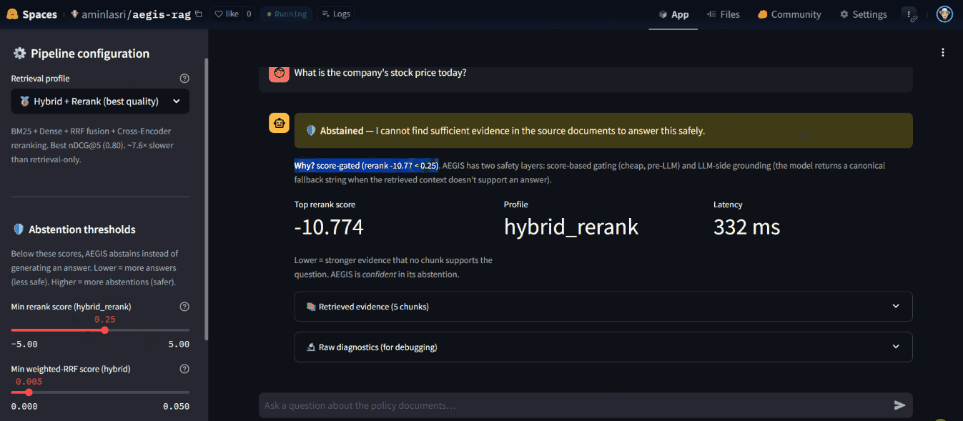
Most RAG systems either generate confident hallucinations or refuse based on a single retrieval threshold. AEGIS uses two complementary safety layers:
- Pre-LLM score gating — abstains when the top rerank score (or fused RRF score) falls below a configured threshold. Cheap, runs before any generation.
- Post-retrieval LLM grounding — the system prompt instructs the model to emit a canonical fallback string when the retrieved chunks don’t actually answer the question. The application detects this and surfaces it as an abstention.
The live demo exposes both layers via a slider, so you can watch them fire on different question types — out-of-scope queries, ambiguous queries, and queries where retrieval succeeds but evidence is weak.
Key Performance Metrics
| Metric | Hybrid | Hybrid + Rerank |
|---|---|---|
| Recall@5 | ~0.82 | 0.85 |
| nDCG@5 | ~0.71 | 0.80 |
| Context Precision | — | 0.83 |
| Latency | ~95 ms | ~720 ms |
Reranking lifts nDCG@5 by 9 points at a 7.6× latency cost — an acceptable trade for policy and compliance domains where ranking precision matters more than throughput.
Core Insights
- Retrieval quality dominates — generation tweaks gave marginal gains; retrieval upgrades gave step-function improvements.
- Reranking is non-negotiable for precision — but throughput-sensitive deployments should serve the
hybridprofile and reserve reranking for high-stakes queries. - Safe abstention is cheaper than fact-checking — refusing weak answers eliminates a category of failures that would otherwise require post-hoc validation.
- Fine-tuning was unnecessary — for small, structured corpora, off-the-shelf embeddings + reranking outperformed any fine-tuning we tested, at a fraction of the cost.
What Didn’t Work
- Naïve top-k retrieval without RRF fusion produced inconsistent rankings between BM25 and dense, especially on multi-hop questions.
- Pure dense retrieval missed exact-wording matches (policy section numbers, defined terms) that BM25 caught trivially.
- Aggressive abstention thresholds initially caused over-refusal on valid edge cases — tuning the slider against a held-out eval set was essential.
- Semantic chunking outperformed recursive chunking for policy text, but at higher ingestion cost. Documented in the failure-mode taxonomy in the repo.
Technical Stack
Python · LangChain · ChromaDB · Sentence-Transformers (E5-large-v2) · BM25 · Cross-Encoders (ms-marco-MiniLM-L-6-v2) · Ollama (llama3.1:8b) · RAGAS · Streamlit · Hugging Face Spaces