Amazon ESCI Search

Two-stage hybrid retrieval over 480k Amazon products — Matryoshka 64-dim FAISS + SPLADE + BM25 → cross-encoder reranking. Production-deployed.
🚀 Try the live demo · 💻 View on GitHub · ⚙️ Raw API
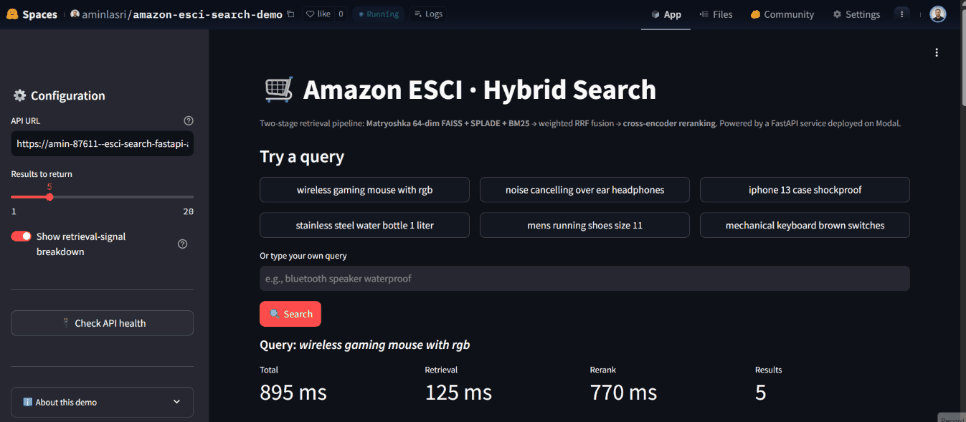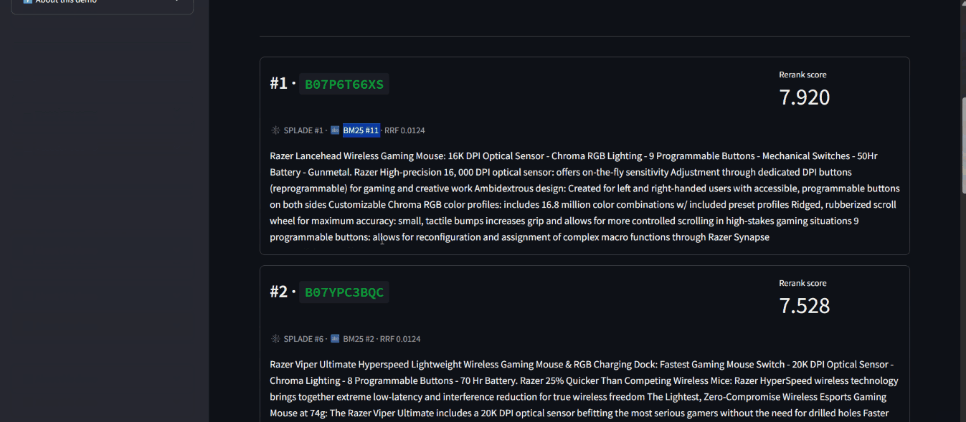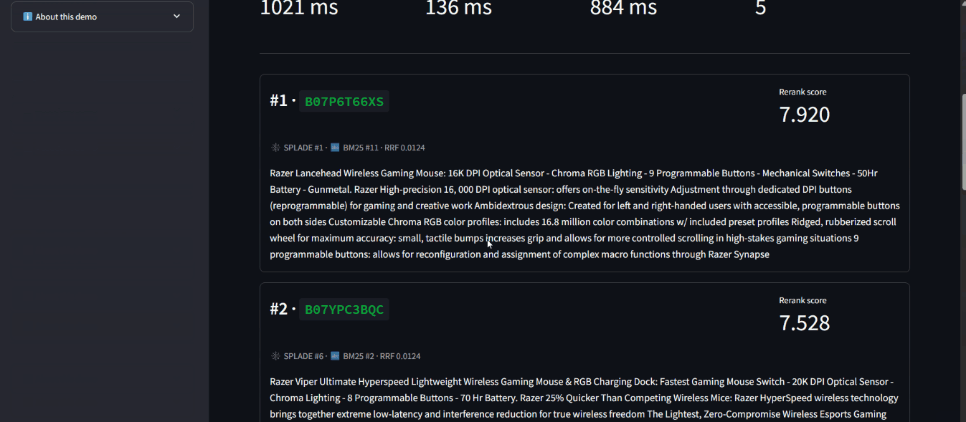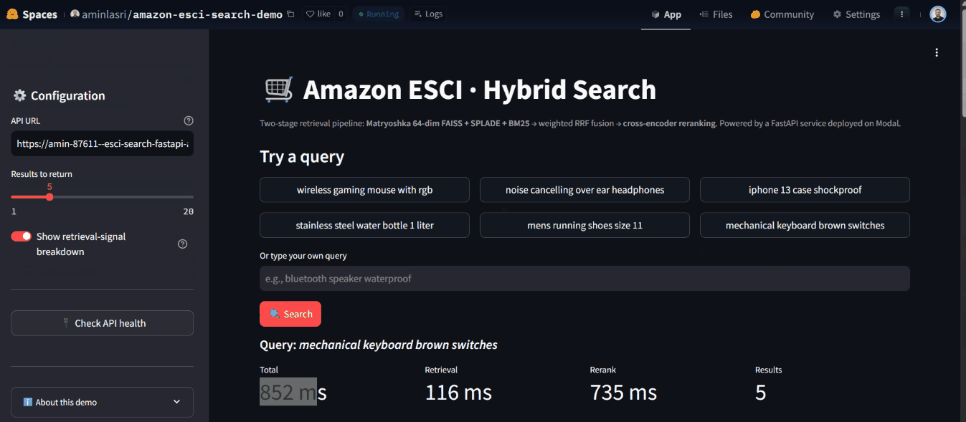
⏱️ Demo cold-start: ~30-60s on first request, ~1 sec after warmup.
The Objective
Build a production-style e-commerce search engine on the Amazon Shopping Queries dataset (ESCI), maximizing ranking precision (nDCG) while compressing vector storage 12× from 768 → 64 dimensions — without sacrificing recall.
The challenge: standard embedding models lose ~50% of their recall when truncated to 64 dimensions. Matryoshka representation learning is supposed to fix that. Does it?
The Architecture & Methodology
A two-stage pipeline with strict separation of concerns:
- Hybrid Candidate Generation
- Dense retrieval: BGE-base fine-tuned with Matryoshka loss, truncated to 64 dims, indexed in FAISS
- Lexical retrieval: BM25 over stemmed product text
- Neural sparse: SPLADE-cocondenser-ensembledistil with pre-encoded inverted index
- All three fused via weighted Reciprocal Rank Fusion (RRF) with separately-tuned weights
- Cross-Encoder Reranking
- Top 200 candidates rescored by
mxbai-rerank-base-v1(deployed demo usesms-marco-MiniLM-L-6-v2for CPU latency) - Final top-K returned with full per-retriever signal breakdown
The Differentiator: Matryoshka @ 64 Dimensions
Most embedding models collapse when truncated. Matryoshka fine-tuning teaches the model to encode the most important features in the first N dimensions, so truncation is principled rather than lossy.
| Strategy | Baseline 64-dim Recall@200 | Matryoshka 64-dim Recall@200 | Δ |
|---|---|---|---|
| Dense Only | 0.43 | 0.74 | +73% |
| Dense + BM25 | 0.56 | 0.78 | +41% |
| Dense + SPLADE | 0.66 | 0.81 | +22% |
| Dense + BM25 + SPLADE | 0.70 | 0.81 | +16% |
At 64 dimensions, hybrid Matryoshka matches the recall of a 768-dim baseline — at one-twelfth the storage and roughly 4× the QPS. All experiments tracked in MLflow on DagsHub.
Key Performance Metrics
| Stage | Recall@200 | nDCG@20 | QPS |
|---|---|---|---|
| Retrieval (hybrid) | 0.8148 | 0.4846 | 69.63 |
| After Reranking | — | 0.5378 | 5.72 |
Reranking adds ~5 points of nDCG@20 at a 12× QPS cost — a clear precision/throughput tradeoff that should be made per-deployment.
Production Deployment
The system is deployed end-to-end, not just benchmarked:
- FastAPI backend containerized and deployed on Modal (CPU, scales to zero, ~1s warm latency)
- Streamlit frontend on Hugging Face Spaces, calling the Modal API
- Persistent Modal Volume holds the 1.7GB of artifacts (FAISS index, SPLADE matrix, BM25, fine-tuned matryoshka weights) — image stays small, cold starts stay reasonable
- Per-result signal breakdown in the API response: every result shows which retrievers found it and at what rank, exposing the hybrid retrieval dynamics that are usually hidden
Core Insights
- Matryoshka representation learning is real and matters — 64-dim Recall@200 = 0.81 vs 0.43 for naive truncation of the same base model
- Hybrid > monolithic — every retriever contributes complementary signal; SPLADE catches what BM25 misses, dense catches what both miss
- Reranking is non-negotiable for precision — but throughput-sensitive deployments should reserve it for high-stakes queries
- Production deployment exposes bugs benchmarks never see — silent vector-space mismatches, CUDA-pickled tensors on CPU containers, sklearn version skew. All documented in the failure-mode log
What Didn’t Work
- Loading the base BGE model in production (instead of the fine-tuned matryoshka) was a silent recall bug — query embeddings ended up in a different vector space than the indexed products. Caught only when productionizing
- Pure RRF without weighted fusion underperformed; SPLADE and BM25 needed lower weights than dense to avoid drowning out semantic signal on long-tail queries
- Cross-encoder on CPU at full top-200 was 16-second-per-query — unusable for live demo. Reduced to top-100 with smaller cross-encoder for ~1s demo latency
- Reranking improves nDCG more than Recall — diminishing returns past Recall@10; the value is reordering, not retrieving
Technical Stack
Python · PyTorch · Sentence-Transformers (BGE-base + Matryoshka loss) · FAISS · BM25 (custom CSR-tensor implementation) · SPLADE · Cross-Encoders · MLflow + DagsHub · FastAPI · Modal (serverless deployment) · Streamlit · Hugging Face Spaces
🚀 Try the live demo · 💻 View on GitHub · 📊 MLflow experiment log